AWS S3 and Single Page Applications
In my previous post, I explained how straightforward it is to host a static website on S3 with HTTPS support and a custom domain. Naturally, this should include Single Page Applications (SPAs) since they're essentially bundles of HTML, JS, CSS, and other assets. However, when combined with S3, SPAs pose unique challenges that manifest under specific circumstances. Let's explore the problem and its solutions.
Problem with SPA
Single Page Applications, as the name suggests, comprise just one HTML file and one or more JS files. The HTML file loads on the initial request, and all the magic happens on the client side through DOM manipulation by the JS code.
Moreover, SPAs often feature a routing component, such as React Router in React's case, which intercepts navigation requests when a link is clicked. Instead of sending an HTTP request to the server to navigate to a sub-page, the router stops the browser from navigating and simply replaces the current content. Despite this, it appears as though you're navigating since the router updates the URL.
For instance, consider this React Router demo app deployed on S3 via static website hosting:
http://spa-hosting-example.s3-website-us-east-1.amazonaws.com
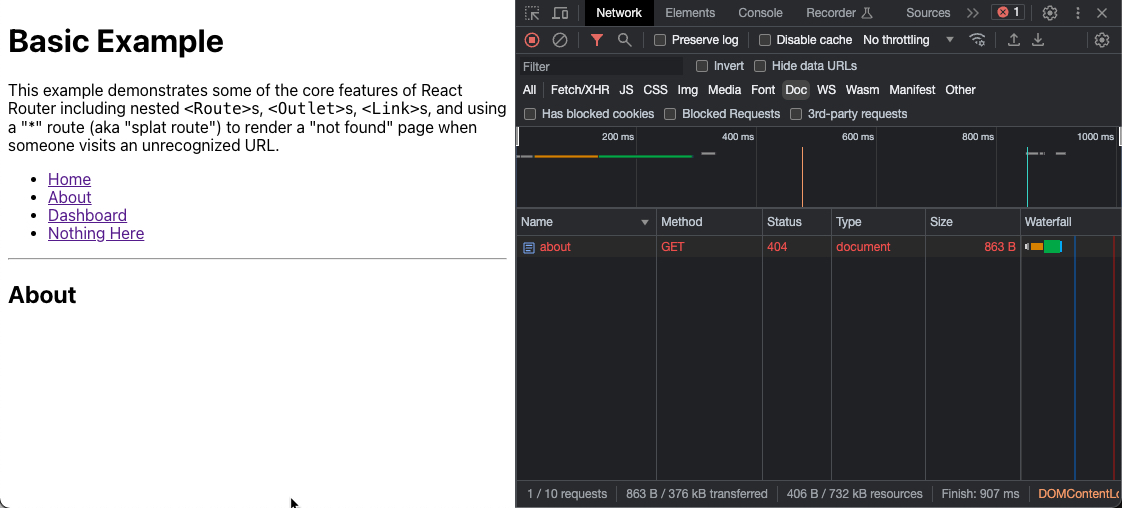
If you navigate to its sub-pages, everything should work smoothly. However, try accessing a sub-page directly or refreshing while on a sub-page like /about:
http://spa-hosting-example.s3-website-us-east-1.amazonaws.com/about
Oops, an error occurred! But why now and not earlier?
The crux of the issue is this: when you access a resource like /about on a S3 website hosting bucket, it will first attempt to fetch the about object from the bucket's root. If this object isn't found, it'll look for about/index.html. If this object isn't found either, it will return 404 Not Found error.
On a side note: It's possible to host a website on S3, but without static website hosting. In this case, CloudFront accesses the S3 bucket via its REST endpoint instead of its HTTP endpoint. In this scenario, the same error would occur, but you would get a 403 Access Denied instead of a 404 Not Found error. This AWS document explains the various reasons for 403 errors.
Solution(s)
This problem can be fixed either via S3 or CloudFront.
S3 Error Document
If you're using S3's static website hosting feature, you can configure an error document for 404 Not Found errors. But, instead of a different document, you'd return the index.html from your SPA bundle. This means unresolved S3 requests will return the index.html document.

It's worth noting that despite responding with the correct index.html, S3 will still send a 404 HTTP response code. The AWS docs highlights that some browsers might override the S3 error document for 404 errors, displaying their own error page instead.
CloudFront Custom Error Response
CloudFront offers functionality similar to S3, enabling customized responses to HTTP error codes. For a 404 Not Found, CloudFront can be set to return the default index.html document. Unlike S3, CloudFront lets us adjust the HTTP response code to 200 OK.

CloudFront Functions
This advanced solution involves CloudFront Functions or Lambda@Edge to inspect all incoming requests and rewrite the URLs, similar to the rewrite-rules from Apache or Nginx.

When this function is assigned to a CloudFront distribution, requests to /about or /about/ will yield the root index.html document. However, users won't perceive this change as it affects only the communication between CloudFront and S3, not between the user and CloudFront.
Be aware that this function is quite rudimentary and will probably require some adjustments and review before it is used in production. For example, it only checks for a dot in the URL, and if absent, changes the URL.
Two official AWS resources delve deeper into CloudFront or Lambda@Edge Functions:
- URL rewrite to append index.html to the URI for single page applications
- Implementing Default Directory Indexes in Amazon S3-backed Amazon CloudFront Origins Using Lambda@Edge
Conclusion
Now, which option should you choose? As is often the case, it depends on your specific needs. S3's error document is the simplest, eliminating the need for additional services like CloudFront. But if you're already using CloudFront for HTTPS and custom domains, it would be logical to employ its custom error response feature. If your SPA isn't limited to a single index.html but has several files located in various subfolders, this method won't work. In this case, it may make sense to opt for the most powerful option and use CloudFront and Lambda@Edge Functions.